根据需要进行以下选择,单击相应的按钮即可:
(1) Wls(Weight Least Squares)按钮:利用加权最小平方法给于观测量不同的权重值,它或许可以用来补偿采用不同测量方式时所产生的误差。这与利用观测值加权而改变有效样本的大小是不同的。为了获得加权最小平方解法设置一个加权变量。对于加权残差分析,将残差与预测值各自保存为新变量,然后将那些新变量与所设置的加权变量的平方根相乘。
单击Wls 按钮在线性回归窗口的底部出现确定加权变量框,如图12-5所示:
先在左侧的源变量框中选择加权变量,再单击Wls Weight 左侧的选入按钮即可。被选择的自变量与因变量不能作为加权变量。加权变量中含有零、负数或缺失值的观测量将会被剔除。
|
图12-5
加权变量框
|
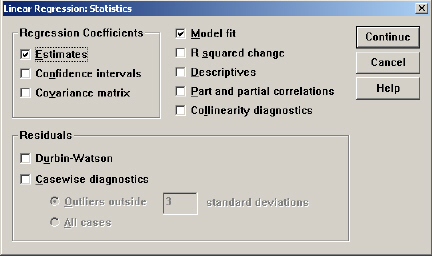
| (2) Statistics按钮:选择不同的选项,进行相关参数的统计。如图12-6所示:
|
图12-6
Statistics对话框
|
①Esthates:提供各变量之间的回归系数、相关统计:在方程式中的变量包括回归系数B、标准误、标准化回归系数beta,t的双侧显著性水平检验;不在方程式中的变量包括beta的t值、t的概率偏相关系数、最小容忍度等统计量。这是默认选择项。
②Confidence intervals:每一个非标准化回归系数95%的可信区间。
③Covarice matrix:非标准化回归系数的方差-协方差。
④Descriptive:变量的平均数、标准差、相关系数单侧显著性水平矩阵。
⑤Model fit:提供相关系数R 、复相关系数平方R2(R squared)、调整系数Ra2(adjusted
R squared)、估计标准误、ANOVA的图表。这是默认选择项。
⑥Block summary:提供回归过程中每一步的统计量(Backward、forwardst、epwise)
⑦Durbin Watson:德宾-沃森检验。同时包含标准化与非标准化残差与预测值的分析。
⑧Collinearity:共线性诊断。其中包括各变量的容限公差以及共线性的诊断表。
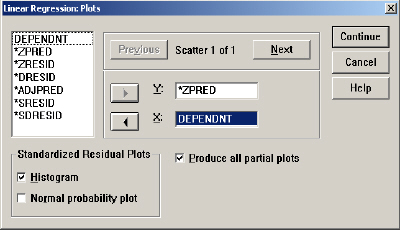
(3) Plots(绘图)按钮:绘制残差散布图、直方国、奇异值图或正常概率图。通过对变量的选择可以确定与y轴(垂直轴)和x轴相对应的变量。为获得更多的图形可以单击next按钮来重复此操作过程。一次最多可以确定九个图形。Plots(绘图)按钮:绘制残差散布图、直方国、奇异值图或正常概率图。通过对变量的选择可以确定与y轴(垂直轴)和x轴相对应的变量。为获得更多的图形可以单击next按钮来重复此操作过程。一次最多可以确定九个图形。对话框如图12-7所示: |
图12-7
Plots对话框
|
①左上角框中的变量的含义为:
DEPENDENT:因变量;
* ZPRED:标准化预测值;
*ZRESID:标准化残差;
*DRESID:剔除残差;
*ADJPRED:调节预测值;
*SRESID:学生化残差;
*SDRESID:学生化剔除残差;
②Produce all partial plots:选择此项可以(针对每一个自变量)产生一个自变量残差相对于因变量残差的散布图。
③standardized Residual Plots:在图中描绘出各变量标准化残差的分布。可以单独选择奇异值(Outliners)或全部观测量(All)。
如果选择奇异值选项,则必须确定以多大的标准化残差值来作为检验观测值是否为奇异值的标准。Outliers outside:如果你确定了是仅仅绘制奇异值的标准化残差图形,那么你必须确定那些可以被绘制的观测量的标准化残差值的标准。默认的标准差的值为3。
如果选择了全部观测量作为选择项并且数据很多时,则输出结果会相对很长。All cases:绘制所有的观测量。
● Histogram(直方图):显示标准化残差的分布。
● Normal probability plot:比较标准化残差与正常残差分布示意。
● Casewise plot:绘制每一个观测量的标准化残差。可以选择绘制所有自变量的标准化残差图形或仅仅是奇异值的标准化残差图形。
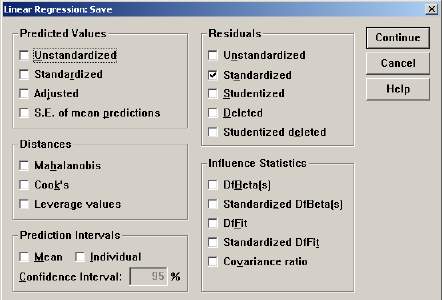
⑷ Save按钮:每项选择都会增加一个或更多的新变量进人你的数据文件。包括预测值、残差等相关统计量。对话框如图12-8所示:
|
图12-8
Save对话框
|
① Predicted Values:预测值
Unstandardized:非标准化预测值;
standardized:标准化预测值;
Adjusted:调节预测值;
S.E. of mean predictions:预测值的标注误。
② Distances:距离
Mahalarnobis:Mahalanobis距离;
Cook' s:cook' s距离;
Leverage values:中心化杠杆值。
③ Prediction intervals:预测区间
Mean:预测区间高低限的平均值;
individual:一个观测量上限与下限的预测间距;
Confidence interval(可信区间):默认值为95%,所键入的值必须在0~100之间。
④Reslduals:残差
Unstandardized:非标准化残差;
standardized:标准化残差;
studentized:学生化残差;
Deleted:剔除残差;
Stundentized Deleted:学生化剔除残差。
⑤influence:影响
DfBeta(s):由排除一个特定的观测值所引起的回归系数的变化。一个用来计算方程式中包括常数项在内的各条目的值;
Standardized Dfbeta(s):标准化的 DfBeta值;
DfFit:由排除一个特定的观测值所引起的预测值的变化;
standardized DfFit:标准化的 DfFit值;
Covariance:带有一个特定的剔除观测值的协方差矩阵与带有全部观测量的协方差矩阵的比率。
(5)Options按钮:改变用于进行逐步回归(Stepwise methods)时的内部数值的设定以及对缺失值的处理方式。对话框如图12-9所示: |
图12-9 Options对话框
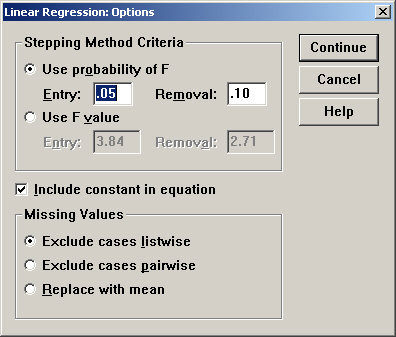
|
①Use probability of F:如果一个变量的F显著性水平值小于所设定的进人值(Entry
value)那么这个变量将会被选人方程式中;如果它的F显著性水平值大于所设定的剔除值(Removal value)那么这个变量将会被剔除。所设定的进人值必须小于剔除值。
②Use F value:如果一个变量的正值大于所设定的进人值(Entry value),那么这个变量将会被选入方程式中;如果它的F值小于剔除值,那么那么这个变量将会被剔除。
③Include constant in equation:选择此项表示在回归方程式中包含常数项。
④Missing value treatments:缺失值处理方式
● Exclude cases listwise:在使用所有带有合法值的变量的同时用F除数据中的剩余观测量;
● Exclude cases pariwise:只是使用那些数据完整并且具有相关关系用来计算相关系数的观自由度的最大值是成对值N;
● Replace with mean:利用变量的平均数代替缺失值。 |